Module not found: Error: Can't resolve 'fs'
If you've set up webpack with an Electron application and you hit this strange error when trying to bundle your project, you've probably forgotten to include the target in your webpack config. This is easily fixed by editing webpack.config.js to include the target, something like this:
const path = require('path');
module.exports = {
entry: './app.js',
output: {
filename: 'bundle.js'
},
target: 'electron'
.
.
.
}
Following along with Free Code Camp's Node course, I was playing with how-to-npm from Node School, I followed the first exercise and ran how-no-npm verify. My npm version was out of date and following the prompt, I ran npm install npm -g. That seemed to complet successfully, however, running how-to-npm verify subsequently gave me a lovely string of errors, the top one being
Error: Cannot find module 'process-nextick-args’
Running any npm command seemed to result in something similar.
To fix this, I did the following - first upgrade Node itself with nvm:
Step 1 - upgrade node itself with nvm:
nvm install v8.9.3
Step 2 - install how-to-npm again:
npm install how-to-npm -g`
Step 3 - upgrade npm
npm i -g npm
Now I can run how-to-npm verify again and everything works
Having set middleman up to be a static blog, you might find yourself wanting to add some static pages outside of the blog structure. For example, if you install any analytics on your site, you often need to include a static file with an authentication code to your analytics provider. These pages are often barebones, with no common header or footer and no styling and you almost certainly do not need them to be processed from markdown. In other words, you want to create a page that does not use the layouts that the rest of your site uses.
To set these up, create the html page and then edit your config.rb to include something like the following:
page "my_barebones_page.html", directory_index: false, layout:false
Using layout: false is reasonably self-explanatory; you are instructing middleman to forego any layout for this page. The inclusion of
directory_index: false makes sure that the page is accessible with the .html suffix. This is especially useful if you are using pretty
urls for your blog.
Rake tasks are easily listed from the command line with rake -T. However if
you've written a rake task and neglected to provide a description for it with
the desc as the first line, the task will not show up with the usual rake -T. These are essentially hidden rake tasks!
To display them, append -A to your normal rake command; so:
rake -T -A
and hey presto, your hidden tasks are visible.
The simplest way to rename a branch in git is first to checkout that branch and
then do something like this:
git branch -m new-branch-name
Technical blogs are usually going to have code examples and if you're a Jekyll refugee exploring Middleman, you'll be accustomed to creating fenced code blocks surrounded by backticks. Something like this:
```
code_block = Codeblock.new(:with_backticks)
```
Middleman uses kramdown to parse and convert Markdown into Html and kramdown by default expects tildes for fenced code blocks:
~~~
code_block = Codeblock.new(:with_tildes)
~~~
To get a backtick flavoured code block, you need to specify a Github Flavoured Markdown (GFM) parser in your config.rb.
To set up your Middleman powered blog so that kramdown accepts backtick fenced code blocks, follow the usual setup guides and then, in config.rb add the following:
set :markdown_engine, :kramdown
set :markdown, fenced_code_blocks: true, input: "GFM"
What are meta tags
Meta tags are, as the name suggests, pieces of html that you add to your web pages to provide meta data. In other words, meta tags describe your web page and can include things like who authored the page, the keywords to associate with the page, a general description of the page and various other pieces of data that apply to your web page but aren't necesary for the end user to see
Why you might want to add meta tags to your shopify page
Meta tags are sometimes used to verify the ownership of a site. For example, if you want to hook up a Pinterest business account to your Shopify shop, Pinterest will ask you to add a meta tag to your site; the assumption being that only the owner of the site will have access to the underlying html and if you manage to shoe-horn your meta tag in, you've basically proven that you own the site.
How to add a meta tag to your Shopify page
The process of adding a meta tag to your Shopify site is pretty simple. It does, however, require you edit the template. Be warned, you'll be diving into the actual code of your chosen theme and modifying that. This can seem scary, but it's pretty simple in reality, and all you are doing is editing text.
Navigate to the store's theme
Log in to Shopify, click on the Online Store under Sales Chanel in the left hand menu.
A secondary menu should slide in and Themes should already be selected for you. If not, click on Themes.
Take a backup
It's always a good idea to backup your theme in case you break something so click on the elipses(three dots) towards the right hand side of the page near the Customize theme button and select Download theme to get a backup emailed to you.
Edit the html/css
Now you have your backup, click on the elipses again and this time select Edit HTML/CSS.
You'll see a file listing in and a helpful message saying 'Pick a file from the left sidebar to start editing'.
In general, you'll need to edit a file called theme.liquid. Shopify uses a special type of markup or templating language which gets converted into HTML, which is why the file has a .liquid extension. These template files are a combination of HTML and essentially ruby code which allows for things like loops and other coding constructs not normally available in plain HTML.
HTML pages (and by extension, liquid templates) contain various sections which are contained within opening and closing tags. One of these sections is called the head. As it's name implies, the head section sits at the top of the page and it's here that meta tags are inserted. If you look at the template for your site, you'll probably already have a few meta tags. That's great.
To inlude your Pinterest meta tag, just copy the meta tag that Pinterest has supplied you and insert it somewhere between the <head> and </head> tags. If you have a few meta tags in your document, that's great, just paste your new one in below those and hit the Save button.
The Pinterest meta tag will probably look something like
<meta name="p:domain_verify" content="987e54321234a678909f7654321234"/>
Below you can see an example of the first few lines of a liquid template with a Pinterest meta tag included and highlighted in yellow.
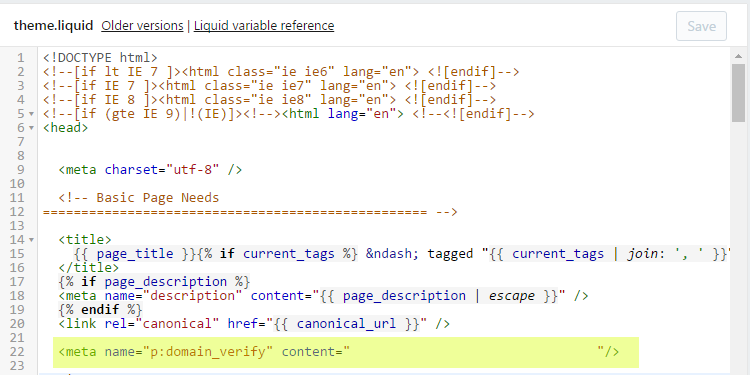
Remember to save your work.
I'm playing with Phoenix and although postgres is supported by default, I wanted to tinker with n sqlite database for a project I'm working on.
It is simple enough to set up esqlite, however, when trying to run mix ecto.migrate, I bumped into the following error:
c_src/esqlite3_nif.c:21:21: fatal error: erl_nif.h: No such file or directory
compilation terminated
Mix was also good enough to inform me
** (Mix) Could not compile dependency esqlite, /home/b/.mix/rebar command failed. If you want to recompile this dependency, please run: mix deps.compile esqlite
To solve this, I had to install the erlang-dev package. I'm running Ubuntu so:
apt-get install erlang-dev
And all is right with the world again.
This is a simple one-liner. Open a terminal and install the font as follows:
sudo apt-get install fonts-inconsolata
With the font installed, you can now set your terminal's font by clicking Edit->Profiles in the terminal menu and then selecting the profile from the windown that pops up and clicking the Edit button. Changing the terminal font should also change your vim font.
Javascript image slideshows or carousels are easy to find on the internet. In fact, you could argue that they are a solved problem and rolling your own is rather pointless. If you are using one of the more popular css frameworks such as Bootstrap or Foundation, you'll already have an image slider/image carousel included in the framework's javascript.
Why then, should you try your hand at coding your own?
Kitchen sink
Most carousels have everything but the kitchen sink. Navigation arrows, captions, keyboard support, slide numbers, slide bullets, play button, pause button, forward button, backward button, transition options, timer options...the list goes on. Infinitely customisable carousels are great, but they come with a cost; time spent learning to use them.
Carousel MVP
Sometimes you really just need a barebones carousel. Something that does nothing more than flip between an array of images. No configuration. No options. No problem.
Dependencies
We are going to lean on jQuery.
Some basic markup
We need some minimal markup for our carousel. A container div if you will. About as simple as I can think is as follows:
<div id="carousel">
</div>
Make the id unique within your own DOM.
It's a common pattern in carousels to place each image in it's own container element - often an li or a div. For this example, I'm going to use div elements as my image containers. Expand your markup to look like this:
<div id="carousel">
<div class="carouselImage">
<img src="/assets/images/images1.jpg">
</div>
<div class="carouselImage">
<img src="/assets/images/images2.jpg">
</div>
<div class="carouselImage">
<img src="/assets/images/images3.jpg">
</div>
</div>
You'll need three images obviously. I'm using some I found on picture of the day.
There are several ways of creating the actual carousel/slideshow effect. One way is to position the three inner divs absolutely in their container element at top and left of 0, 0. In this way, the images are directly on top of each other. To give a carousel effect, show one image at a time, hiding the others. This works well.
A different approach is to position the divs next to each other within their container, ensure the container has overflow:hidden and adjust the left offset of the container to bring images into and out of view. This panorama approach trades managing visibility for managing position. This also works well.
We will work with the first approach, for no particular reason.
Javascript
Our Javascript's task is to control which image is on display. To do this, we will toggle a class on the relevant carouselImage element. Our jQuery work starts off setting this class (let's call it active) against our first image:
$(function() {
$('.carouselImage').first().addClass('active');
});
All good carousels need a timer. Javascript provides the setInterval function to help us create an event that fires at specified intervals. We will start off with once every five seconds. Append the following to your code from above:
setInterval(function() {
},5000);
});
Now we need to toggle the active class of two images - we need the next image in the list to become active and we need to remove the active class from our current image. The added complexity here is if our current image is the last image in the set, we need to loop back round to the first image. Here's the code we need:
setInterval(function() {
$currentImage = $('.carouselImage.active');
$nextImage = $currentImage.next();
// if our current image is the last in our group of images,
// our next image will not exist
if($nextImage.length === 0) {
$nextImage = $('.carouselImage').first();
}
$currentImage.removeClass('active');
$nextImage.addClass('active');
},5000);
});
We start by finding our currently selected image and stashing it in a variable $currentImage. The first time we hit this it should be our first carouselImage element because we explicitly set it to be active earlier. Then we use jQuery's next() function to select the next sibling of our current image. jQuery's next() will try to find the next element sitting at the same hierarchical level of the DOM. In our case we have three siblings at the carouselImage level of the DOM.
To determine whether or not we are displaying the last of our images, we need to test that there really is a next sibling. In jQuery, we do this by testing the length of the object we've tried to find. If the length is 0, we have no object and in our code, that means our current active carouselImage is the last one. Although in the above code, I'm explicitly testing for $nextImage.length === 0, you'll quite often see this code as !$nextImage.length because in Javascript, 0 is a falsy value. Inside our if statement, we use the handy first() function to select the first carouselImage element, just as we did earlier.
The final two lines of code simply remove the active class from our currently active carouselImage element and add the active class to the next carouselImage element we want to become visible.
If you run this code now, nothing will happen because we still haven't put any styling together. I say nothing, but if you pull up the developer tools on your browser, you can watch the active class being set and removed against the carouselImage elements.

Style
All that remains now, is to set some styling.
<style>
.carouselImage {
position: absolute;
left: 0;
top: 0;
display: none;
}
.carouselImage.active {
display: block;
}
</style>
Great - we set each .carouselImage to sit at the top left of its container element. Then we make sure they are hidden by setting display to none. We could use visibility instead of display, but setting the visibility of an item keeps it's position in the layout. Setting display to none actually removes the item from the layout so it essentially takes no space. The .active class simply sets the display to block so that the element is shown.
Credits
Images grabbed from the wonderful Wikimedia image of the day archives.
- Pont sur l'Orb by Christian Ferrer
- Horsehair parachute by Ireen Trummer
- Castle ruins of Aggstein by Uoaei1
{kind=link}
{kind=link}
{kind=link}